Goal
By the end of this tutorial, we will have a technique for restricting UML Stereotype values with regular expressions using the Eclipse UML2 Tools and Ecore ExtendedMetaData.
Create a UML Profile
First, we will need to install the Modelling - > UML2 Tools SDK from the Galileo update site. Make yourself a peanut butter sandwich while you wait for the download, or if you already have the tools, then eat a piece of chocolate as a reward for not eating all those calories.
Our project is to create a Stereotype called Contact, which extends UML::Actor. A Contact is an Actor with contact information, which, in this case, is a single phone number. A US phone number can easily be validated with a regular expression. For this project, we can assume that all the Actors we will ever deal with will have US phone numbers.
We will start off by creating a plain ol' project, here called UML Regex Validation, and in this project, we will create a new UML Profile Definition, RegexValidation.profile.uml, with a Profile Model object as the root.
Since a Contact is an Actor, we will import uml::Actor from the UML Editor -> Profile -> Reference Metaclass menu.
Now we can create our Contact Stereotype and extend uml::Actor from the UML Editor -> Stereotype -> Create Extension menu.
We now have a simple Stereotype that we can apply to an Actor.
From the UML Editor -> Profile -> Define menu, we will generate our initial RegexValidation Ecore UML MetaData.
Test The Stereotype
We can create an Activity Diagram file, RegexValidationTest.uml, with a Package as the root. In the root Package, Contacts, we will create an Actor. Some call him Tim.
From the UML Editor menu, we will load the resource RegexValidation.profile.uml and apply the Profile for RegexValidation to Contacts. We are now ready to apply the RegexValidation::Contact Stereotype to Tim.
Now that we know that we can apply the Profile and the Stereotype, we will remove the Profile and Stereotype applications in RegexValidationTest.uml. When we re-define our Profile, the XMI IDs will also all be re-generated and these Profile and Stereotype applications will be invalidated.
The Restricted Stereotype Attribute
In RegexValidation.profile.uml, we will create our custom Primitive Type, USPhoneNumberType.
The General of this type should be UMLPrimitiveTypes::String.
Now we can add an EAnnotation to the USPhoneNumberType, with source value http:///org/eclipse/emf/ecore/util/ExtendedMetaData.
We will set the ExtendedMetaData Details as follows:
- name -> USPhoneNumberType
- baseType -> http://www.eclipse.org/emf/2003/XMLType#string
- pattern -> 1?\W*([2-9][0-8][0-9])\W*([2-9][0-9]{2})\W*([0-9]{4})(\se?x?t?(\d*))?
This particular US phone number regular expression is based on the NANP specification.
We will also need to apply the Ecore Profile to the RegexValidation Profile in order to Stereotype the USPhoneNumberType as an Ecore::EDataType. We will send Ecore a hint that the USPhoneNumberType Instance Class Name should be java.lang.String.
Now, we can create an Owned Property, PhoneNumber, in the Contact Stereotype, and its type can be RegexValidation::USPhoneNumberType.
We will again Define our RegexValidation Profile from the UML Editor menu, but now we must explicitly Process the Annotation Details in the configuration dialog. The default configuration simply reports on Ecore MetaData.
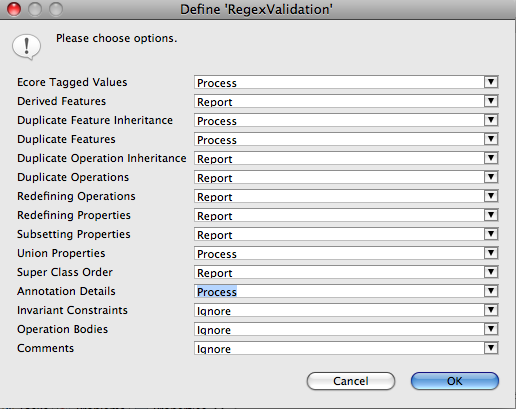
If you are curious, the details section of the status dialog should indicate what MetaData has been processed.
The generated UML MetaData Definition will now include an EDataType for the USPhoneNumberType, which is restricted by our NANP phone number pattern.
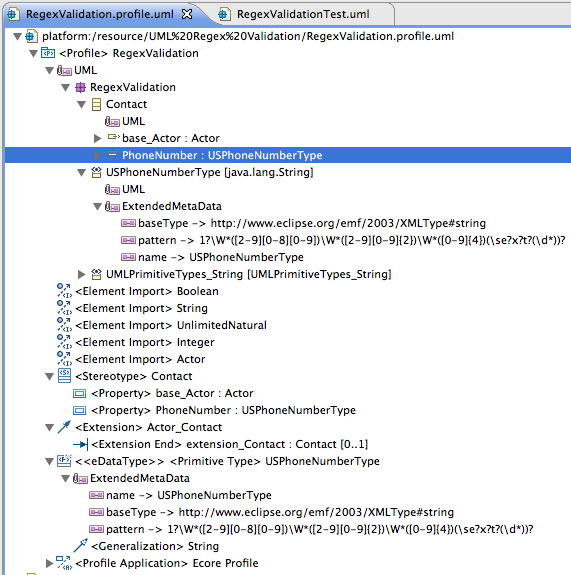
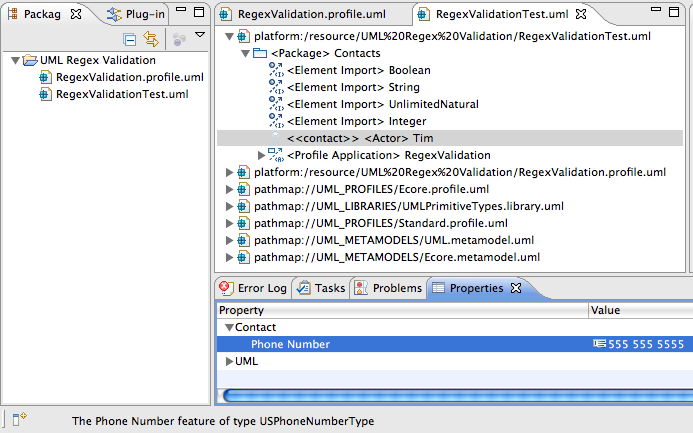
We can now re-open our RegexValidationTest.uml, re-apply the RegexValidation Profile to the Contacts Package, and re-apply the RegexValidation::Contact Stereotype to Tim, the Actor.
We should now see our new PhoneNumber attribute in the Properties View.
Try entering an invalid phone number, such as 123-456-7890, in the Properties text field. What do you see? When you press enter, is the invalid value bound to the attribute?
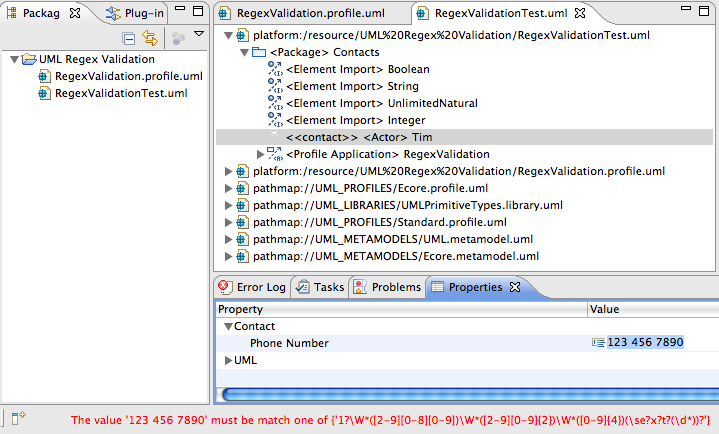
Now try entering a valid phone number, such as 555-555-5555. What happens?
Common Types
With the technique outlined above, common regular expression patterns can be easily applied to more UML Stereotype attributes through Ecore MetaData: URIs, email addresses (although, the more complete regex has given me the SPOD in Eclipse in the past), or any number of other publicly available regular expressions.
Next
Now that we have a way to constrain stereotype attributes with a RegEx, wouldn't it be swell if there were a way to test that the restrictions work as expected?