
Goal
To generate a reasonably accurate JaCoCo code coverage report for a Scala project.
tl;dr
A Maven plug-in for creating JaCoCo code coverage reports is available on github and will be a helpful resource for following this article. This project contains an example that integrates Maven, JaCoCo and ScalaTest with this plug-in and can be used as a template for your own projects. The interesting technologies showcased include JaCoCo and Scala.
The Project
Suppose our development team would like to track how much of our Scala code is covered by our test suite. Now suppose we would like to configure Maven to generate these reports with each build.
Using The Jacoco Maven Plug-in
The JaCoCo Maven plug-in can easily be configured to record and report coverage metrics for compiled Scala because JaCoCo uses a java agent to instrument bytecode on the fly. For example, given a project with standard layout, where Example.scala and ExampleSpec.scala represent a worker and its ScalaTest specification, then the pom configuration is fairly straightforward.
The project layout
jacoco-scalatest-maven-plugin-example
.
|____pom.xml
| src
| | main
| | | scala
| | |____Example.scala
| src
| | test
| | | scala
| | |____ExampleSpec.scala
pom.xml
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>timezra.maven</groupId>
<artifactId>jacoco-scalatest-maven-plugin-example</artifactId>
<version>0.6.3.2-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>org.scalatest</groupId>
<artifactId>scalatest_2.10</artifactId>
<version>2.0.RC2</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>0.6.3.201306030806</version>
<executions>
<execution>
<id>pre-test</id>
<goals>
<goal>prepare-agent</goal>
</goals>
</execution>
<execution>
<id>post-integration-test</id>
<phase>post-integration-test</phase>
<goals>
<goal>report</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.16</version>
<configuration>
<skipTests>true</skipTests>
</configuration>
</plugin>
<plugin>
<groupId>org.scalatest</groupId>
<artifactId>scalatest-maven-plugin</artifactId>
<version>1.0-RC1</version>
<configuration>
<reportsDirectory>${project.build.directory}/surefire-reports</reportsDirectory>
<junitxml>.</junitxml>
</configuration>
<executions>
<execution>
<id>test</id>
<phase>integration-test</phase>
<goals>
<goal>test</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Traits and Mixed-in Methods
Unfortunately, this configuration will soon begin reporting false negative results when even the most basic Scala features are employed. For example, suppose our Example class extends a Scala trait.
ExampleTrait.scala
def thisIsMixedIn() {
println("Hello world")
}
}
TraitExample.scala
def sayHello() {
println("Hello world")
}
}
ExampleSpec.scala
class ExampleSpec extends FunSpec {
describe("A Canary") {
it("should cover a class that mixes in a trait") {
val traitExample = new TraitExample
traitExample.sayHello
}
}
}
The coverage results show a false negative result for the mixed-in method ExampleTrait#thisIsMixedIn. We expect to see 100% coverage but instead see 75%.
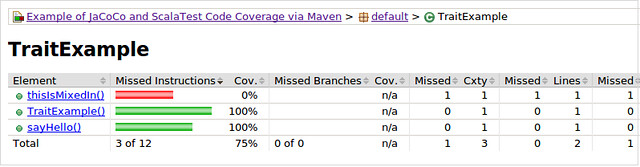
We can see from the bytecode for ExampleTrait that the Scala compiler mixes in traits by generating bytecode for methods in the extending classes and these generated methods delegate to the implemented traits via static calls.
public void thisIsMixedIn();
0 aload_0 [this]
1 invokestatic ExampleTrait$class.thisIsMixedIn(ExampleTrait) : void [17]
4 return
Line numbers:
[pc: 0, line: 22]
Local variable table:
[pc: 0, pc: 5] local: this index: 0 type: TraitExample
....
public TraitExample();
0 aload_0 [this]
1 invokespecial java.lang.Object() [35]
4 aload_0 [this]
5 invokestatic ExampleTrait$class.$init$(ExampleTrait) : void [38]
8 return
Line numbers:
[pc: 0, line: 22]
Local variable table:
[pc: 0, pc: 9] local: this index: 0 type: TraitExample
}
We can also see from the bytecode that the line numbers for the mixed-in method and the constructor are the same. Perhaps this coincidence can give us enough information to filter out these types of false negatives from our coverage report.
Case Classes
Similarly, case classes generate even more bytecode for methods that can be excluded from our coverage reports.
CaseExample.scala
greeting: String = "Hello",
name: String = "world") {
def sayHello() {
println(s"${greeting} ${name}")
}
}
ExampleSpec.scala
class ExampleSpec extends FunSpec {
describe("A Canary") {
it("should cover a case class") {
val caseExample = new CaseExample
caseExample.sayHello
}
}
}
The coverage results show significantly more false negative results for mixed-in and generated methods. We expect to see coverage results closer to 100% than to 32%.
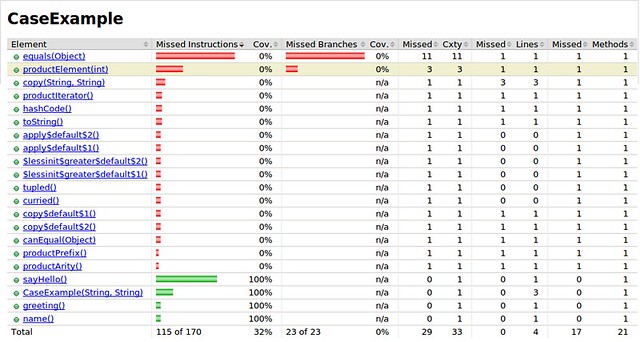
Again, we can see from the bytecode that the line numbers for the mixed-in methods and the constructor are the same. We can also see from the bytecode that generated methods follow a pattern: curried(), tupled() and (\w|\$)+\$default\$\d+\(\) methods. These methods unfortunately cannot be filtered by their debug line numbers, but they can be identified consistently by name. This information may be sufficient for eliminating these false negative results so that our coverage trend can at least look more reasonable even if not exact.
private final java.lang.String greeting;
private final java.lang.String name;
public static java.lang.String apply$default$2();
0 getstatic CaseExample$.MODULE$ : CaseExample. [20]
3 invokevirtual CaseExample$.apply$default$2() : java.lang.String [22]
6 areturn
public static java.lang.String apply$default$1();
0 getstatic CaseExample$.MODULE$ : CaseExample. [20]
3 invokevirtual CaseExample$.apply$default$1() : java.lang.String [25]
6 areturn
public static java.lang.String $lessinit$greater$default$2();
0 getstatic CaseExample$.MODULE$ : CaseExample. [20]
3 invokevirtual CaseExample$.$lessinit$greater$default$2() : java.lang.String [28]
6 areturn
public static java.lang.String $lessinit$greater$default$1();
0 getstatic CaseExample$.MODULE$ : CaseExample. [20]
3 invokevirtual CaseExample$.$lessinit$greater$default$1() : java.lang.String [31]
6 areturn
public static scala.Function1 tupled();
0 getstatic CaseExample$.MODULE$ : CaseExample. [20]
3 invokevirtual CaseExample$.tupled() : scala.Function1 [35]
6 areturn
public static scala.Function1 curried();
0 getstatic CaseExample$.MODULE$ : CaseExample. [20]
3 invokevirtual CaseExample$.curried() : scala.Function1 [38]
6 areturn
public java.lang.String greeting();
0 aload_0 [this]
1 getfield CaseExample.greeting : java.lang.String [43]
4 areturn
Line numbers:
[pc: 0, line: 23]
Local variable table:
[pc: 0, pc: 5] local: this index: 0 type: CaseExample
public java.lang.String name();
0 aload_0 [this]
1 getfield CaseExample.name : java.lang.String [47]
4 areturn
Line numbers:
[pc: 0, line: 24]
Local variable table:
[pc: 0, pc: 5] local: this index: 0 type: CaseExample
....
public CaseExample copy(java.lang.String greeting, java.lang.String name);
0 new CaseExample [2]
3 dup
4 aload_1 [greeting]
5 aload_2 [name]
6 invokespecial CaseExample(java.lang.String, java.lang.String) [95]
9 areturn
Line numbers:
[pc: 0, line: 22]
[pc: 4, line: 23]
[pc: 5, line: 24]
[pc: 6, line: 22]
Local variable table:
[pc: 0, pc: 10] local: this index: 0 type: CaseExample
[pc: 0, pc: 10] local: greeting index: 1 type: java.lang.String
[pc: 0, pc: 10] local: name index: 2 type: java.lang.String
public java.lang.String copy$default$1();
0 aload_0 [this]
1 invokevirtual CaseExample.greeting() : java.lang.String [76]
4 areturn
Line numbers:
[pc: 0, line: 23]
Local variable table:
[pc: 0, pc: 5] local: this index: 0 type: CaseExample
public java.lang.String copy$default$2();
0 aload_0 [this]
1 invokevirtual CaseExample.name() : java.lang.String [78]
4 areturn
Line numbers:
[pc: 0, line: 24]
Local variable table:
[pc: 0, pc: 5] local: this index: 0 type: CaseExample
public java.lang.String productPrefix();
0 ldc
2 areturn
Line numbers:
[pc: 0, line: 22]
Local variable table:
[pc: 0, pc: 3] local: this index: 0 type: CaseExample
public int productArity();
0 iconst_2
1 ireturn
Line numbers:
[pc: 0, line: 22]
Local variable table:
[pc: 0, pc: 2] local: this index: 0 type: CaseExample
public java.lang.Object productElement(int x$1);
0 iload_1 [x$1]
1 istore_2
2 iload_2
3 tableswitch default: 24
case 0: 46
case 1: 39
24 new java.lang.IndexOutOfBoundsException [105]
27 dup
28 iload_1 [x$1]
29 invokestatic scala.runtime.BoxesRunTime.boxToInteger(int) : java.lang.Integer [111]
32 invokevirtual java.lang.Object.toString() : java.lang.String [114]
35 invokespecial java.lang.IndexOutOfBoundsException(java.lang.String) [117]
38 athrow
39 aload_0 [this]
40 invokevirtual CaseExample.name() : java.lang.String [78]
43 goto 50
46 aload_0 [this]
47 invokevirtual CaseExample.greeting() : java.lang.String [76]
50 areturn
Line numbers:
[pc: 0, line: 22]
Local variable table:
[pc: 0, pc: 51] local: this index: 0 type: CaseExample
[pc: 0, pc: 51] local: x$1 index: 1 type: int
Stack map table: number of frames 4
[pc: 24, append: {int}]
[pc: 39, same]
[pc: 46, same]
[pc: 50, same_locals_1_stack_item, stack: {java.lang.String}]
public scala.collection.Iterator productIterator();
0 getstatic scala.runtime.ScalaRunTime$.MODULE$ : scala.runtime.ScalaRunTime. [126]
3 aload_0 [this]
4 invokevirtual scala.runtime.ScalaRunTime$.typedProductIterator(scala.Product) : scala.collection.Iterator [130]
7 areturn
Line numbers:
[pc: 0, line: 22]
Local variable table:
[pc: 0, pc: 8] local: this index: 0 type: CaseExample
public boolean canEqual(java.lang.Object x$1);
0 aload_1 [x$1]
1 instanceof CaseExample [2]
4 ireturn
Line numbers:
[pc: 0, line: 22]
Local variable table:
[pc: 0, pc: 5] local: this index: 0 type: CaseExample
[pc: 0, pc: 5] local: x$1 index: 1 type: java.lang.Object
public int hashCode();
0 getstatic scala.runtime.ScalaRunTime$.MODULE$ : scala.runtime.ScalaRunTime. [126]
3 aload_0 [this]
4 invokevirtual scala.runtime.ScalaRunTime$._hashCode(scala.Product) : int [138]
7 ireturn
Line numbers:
[pc: 0, line: 22]
Local variable table:
[pc: 0, pc: 8] local: this index: 0 type: CaseExample
public java.lang.String toString();
0 getstatic scala.runtime.ScalaRunTime$.MODULE$ : scala.runtime.ScalaRunTime. [126]
3 aload_0 [this]
4 invokevirtual scala.runtime.ScalaRunTime$._toString(scala.Product) : java.lang.String [142]
7 areturn
Line numbers:
[pc: 0, line: 22]
Local variable table:
[pc: 0, pc: 8] local: this index: 0 type: CaseExample
public boolean equals(java.lang.Object x$1);
0 aload_0 [this]
1 aload_1 [x$1]
2 if_acmpeq 92
5 aload_1 [x$1]
6 instanceof CaseExample [2]
9 ifeq 96
12 aload_1 [x$1]
13 checkcast CaseExample [2]
16 astore_2
17 aload_0 [this]
18 invokevirtual CaseExample.greeting() : java.lang.String [76]
21 aload_2
22 invokevirtual CaseExample.greeting() : java.lang.String [76]
25 astore_3
26 dup
27 ifnonnull 38
30 pop
31 aload_3
32 ifnull 45
35 goto 88
38 aload_3
39 invokevirtual java.lang.Object.equals(java.lang.Object) : boolean [145]
42 ifeq 88
45 aload_0 [this]
46 invokevirtual CaseExample.name() : java.lang.String [78]
49 aload_2
50 invokevirtual CaseExample.name() : java.lang.String [78]
53 astore 4
55 dup
56 ifnonnull 68
59 pop
60 aload 4
62 ifnull 76
65 goto 88
68 aload 4
70 invokevirtual java.lang.Object.equals(java.lang.Object) : boolean [145]
73 ifeq 88
76 aload_2
77 aload_0 [this]
78 invokevirtual CaseExample.canEqual(java.lang.Object) : boolean [147]
81 ifeq 88
84 iconst_1
85 goto 89
88 iconst_0
89 ifeq 96
92 iconst_1
93 goto 97
96 iconst_0
97 ireturn
Line numbers:
[pc: 0, line: 22]
Local variable table:
[pc: 0, pc: 98] local: this index: 0 type: CaseExample
[pc: 0, pc: 98] local: x$1 index: 1 type: java.lang.Object
Stack map table: number of frames 9
[pc: 38, full, stack: {java.lang.String}, locals: {CaseExample, java.lang.Object, CaseExample, java.lang.String}]
[pc: 45, same]
[pc: 68, full, stack: {java.lang.String}, locals: {CaseExample, java.lang.Object, CaseExample, java.lang.String, java.lang.String}]
[pc: 76, same]
[pc: 88, chop 1 local(s)]
[pc: 89, same_locals_1_stack_item, stack: {int}]
[pc: 92, chop 2 local(s)]
[pc: 96, same]
[pc: 97, same_locals_1_stack_item, stack: {int}]
public CaseExample(java.lang.String greeting, java.lang.String name);
0 aload_0 [this]
1 aload_1 [greeting]
2 putfield CaseExample.greeting : java.lang.String [43]
5 aload_0 [this]
6 aload_2 [name]
7 putfield CaseExample.name : java.lang.String [47]
10 aload_0 [this]
11 invokespecial java.lang.Object() [149]
14 aload_0 [this]
15 invokestatic scala.Product$class.$init$(scala.Product) : void [155]
18 return
Line numbers:
[pc: 0, line: 23]
[pc: 5, line: 24]
[pc: 10, line: 22]
Local variable table:
[pc: 0, pc: 19] local: this index: 0 type: CaseExample
[pc: 0, pc: 19] local: greeting index: 1 type: java.lang.String
[pc: 0, pc: 19] local: name index: 2 type: java.lang.String
}
JaCoCo Scala Maven Plugin
The JaCoCo project maintainers are currently in the process of collecting use cases for the types of configurable filtering options that the community needs. Until that general-purpose solution has been implemented, the jacoco-scala-maven-plugin can be used to fulfill two of those specific filtering needs, i.e., SCALAC.MIXIN and SCALAC.CASE. These two filters eliminate methods that have the same debug line numbers as the constructor and the names tupled(), curried() and (\w|\$)+\$default\$\d+\(\), as noted above.
In our pom, instead of configuring the jacoco-maven-plugin to emit a report, we can now pass these two filtering options to the jacoco-scala-maven-plugin.
pom.xml
....
<build>
....
<plugins>
....
<plugin>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>0.6.3.201306030806</version>
<executions>
<execution>
<id>pre-test</id>
<goals>
<goal>prepare-agent</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>timezra.maven</groupId>
<artifactId>jacoco-scala-maven-plugin</artifactId>
<version>0.6.3.1</version>
<executions>
<execution>
<id>post-integration-test</id>
<phase>post-integration-test</phase>
<goals>
<goal>report</goal>
</goals>
<configuration>
<filters>
<filter>SCALAC.CASE</filter>
<filter>SCALAC.MIXIN</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
....
</plugins>
</build>
<pluginRepositories>
<pluginRepository>
<id>tims-repo</id>
<url>http://timezra.github.com/maven/releases</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</project>
When using these two filters, the coverage results for the TraitExample and CaseExample no longer include generated and mixed-in methods, and instead give us a more accurate coverage score of 100% for both.
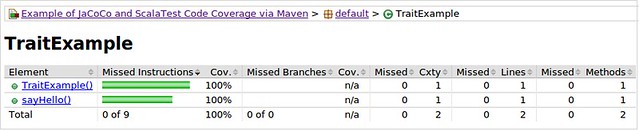

Conclusion
By examining and resolving anomalies in the code coverage statistics for our project through the introduction of a jacoco-scala-maven-plugin, we have gained an insight into how the Scala compiler mixes and injects methods into generated bytecode (which can also give insight into how Scala is able to chain super calls when multiple traits are linearized). While there are certainly other generated instructions that can be ignored during a coverage run, these two filters get us closer to being able to gather useful coverage trend information over time.
If you notice any other filtering options that you would like to see from the jacoco-scala-maven-plugin, please let me know, either here or on github.
7 comments:
Long Path Tool help me a lot when i have an issue like file deleting or renaming the file. Also good to use if file name and file extension is too long.
“Long Path Tool” is very helpful for this error !
You can use to solve this problem
“Long Path Tool” is very helpful for this error !
best solution for your problem.
thanks for sharing this information
aws training center in chennai
aws training in chennai
aws training in omr
aws training in sholinganallur
aws training institute in chennai
best aws training in sholinganallur
Just saying thanks will not just be sufficient, for the fantasti c lucidity in your writing. I will instantly grab your rss feed to stay informed of any updates.
360DigiTMG pmp course in malaysia
360DigiTMG pmi certification
360DigiTMG
This is excellent! We have exactly the same problem. But we are using gradle but not maven. Is there a gradle plugin for this?
Excellent post, Thanks for sharing this.
Learn more about our courses to get the best knowledge. CSPO Certification
Post a Comment