Note:
this post is a continuation of The ODA-Ecore Getting Started Guide and assumes that you are familiar with its contents and the examples presented therein.Creating a Master-Details Report
Suppose we want to report on all the Writers and their Books in a model. Each Writer's name should appear in the Master part of the report. Each of the Writer's Books should appear as a Detail and should display the Title, Number of Pages and the Category for the Book.
There are at least two solutions with the current implementation of the enablement plug-in.
EReference ResolutionThe ODA-Ecore enablement plug-in supports EReference resolution. For any EObject that contains a reference to another EObject, it is possible to display the value of a particular EAttribute of that EReference (or an EAttribute of an EReference to an EReference, etc.). It is also possible to display the value of the full EReference itself (which is just a toString() of the EObject that is referenced). A user selects EAttributes of EReferences when creating a new Data Set in the Data Set Columns Wizard Page. Collections of References are returned as a <cr>-delimited String of the selected EAttributes for an EReference. The more deeply nested the EAttribute or EReference, the more dificult interpretation of the results becomes, which is why this method is prefered only in simple cases.
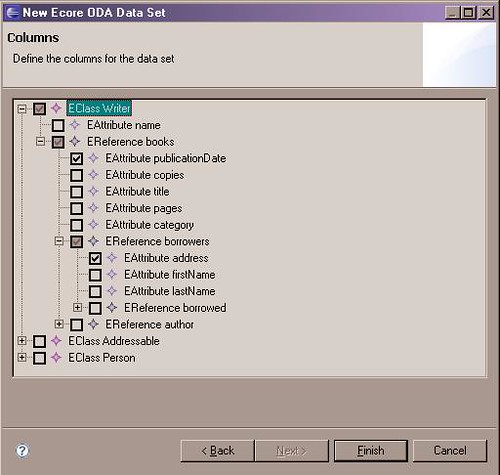
In this selection, we have chosen to output the publicationDate of any books written by a particular Writer, along with the address of any borrowers of the books written by the Writer.
Using EReferences is a simple solution, but it is limited in the general case. For such a simple use case, it will satisfy our needs, however.
From the Query Wizard Page, select Writer as the Invariant.
As your Boolean Query, use "self.oclIsKindOf(Writer)".
From the Columns Wizard Page, select
- Writer::name
- Writer::books::title
- Writer::books::pages
- Writer::books::category
In the BIRT report, we will insert a new table with 1 columns and 2 details. The first details row will be the Master part, the second will be the Details part.
In column 1 of the first detail row, we will drag Writer::name from the Data Set.
In the second detail row, we will insert a new table with 2 columns and 1 detail. The first column is for spacing, the second will contain the EAttribute values (for the Details part).
In the detail row of the second column of the nested table, we will insert another table with 3 columns and 1 detail row.
Finally, into these 3 columns, we will drag Writer::books::title, Writer::books::pages and Writer::books::category from the Data Set.
We could remove the header information and re-space the columns to get the layout of the information that we want.
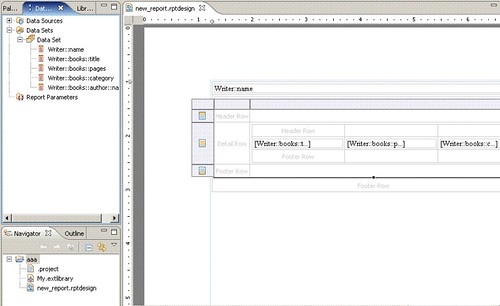
The Layout of the Report using EReference Resolution for Master-Details display.
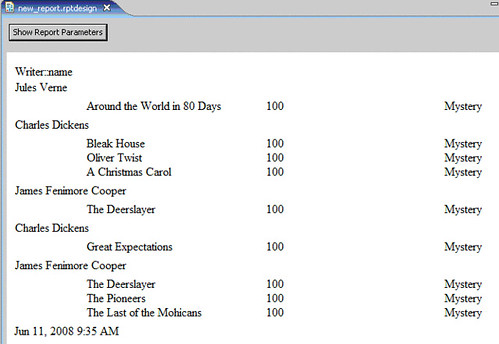
We have achieved our goal using three nested tables and a single query that resolves EReferences.
Joining ResultSetsParameterizing the BooleanOCLQuery and and using multiple joined data sets are solutions for more complex situations.
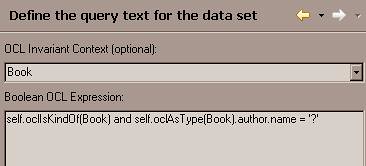
each ? in the query is replaced with the input parameters in order (the first ? is replaced with the first parameter, the second ? is replaced with the second parameter, etc.). Named parameters are not yet supported.
For the example stated above (a Master-Details table of each Writer's name as the Master with information about all the Writer's Books as the Detail.)
1. Create a DataSource and point it to the Extlibrary file.
2. Create a DataSet called "Writers Data Set" with these features:
- Invariant -- Writer
- Query -- self.oclIsKindOf(Writer)
- Selected Column -- Writer::name
3. Create a DataSet called "Books Data Set" with these features:
- Invariant -- Book
- Query -- self.oclIsKindOf(Book) and self.oclAsType(Book).author.name = '?'
- Selected Columns -- Book::title, Book::pages, Book::category, Book::author::name (just to prove out what we are doing)
- Parameters -- input param1 with default value 'James Fenimore Cooper' (make sure you use quotes or you will get a Javascript error).
4. Drag the Writers Data Set into the Report and name the Table "Writers List". This is the Master part.
5. Add a column to the right of the Writer::name column.
6. Drag the Books Data Set into the empty column. This is the Details part.
7. Select the Books Data Set Table and add a Data Set Parameter Binding from Writer::name to param1.
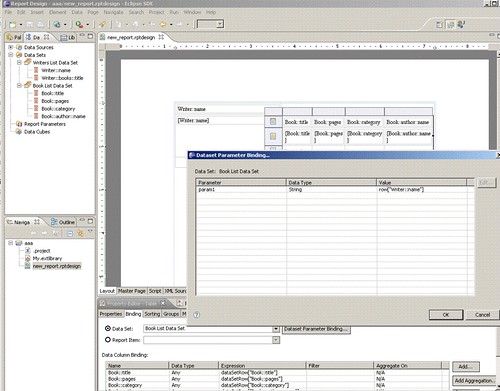
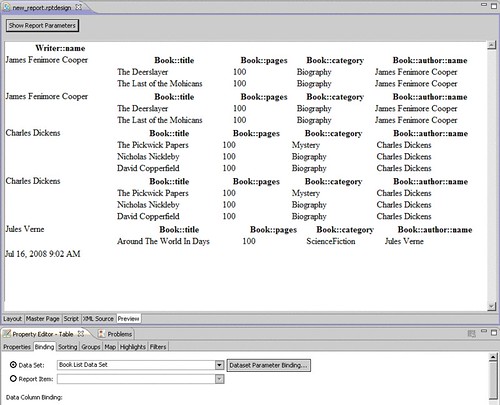
8. Select Preview and you should now see a Master-Details report that lists the Writers' names in the first column and, for each Writer, a list of the Books associated to that Writer in a nested table in the right column.
Sorting Results
Suppose we need to sort or filter the results of a query. As only Boolean OCL queries are supported by the enablement plug-in, the driver does not currently support a SORT BY feature in the OCL query itself. Fortunately,
BIRT's sorting and filtering mechanism for groups should satisfy many of our needs.
Suppose we want to find all the Writers in the object graph and print their names. In the Wizard to form the DataSet, we would choose "Writer" from the dropdown, our query would be "self.oclIsKindOf(Writer)", and we would choose to report on the column "Writer::name".
For the report, we can drag the Data Set from the Data Explorer to the report.
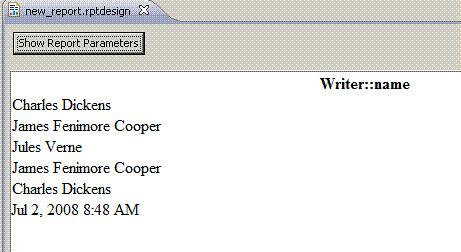
The unsorted preview of this report.
In the Detail Row, instead of using "[Writer::name]", we will delete the Detail row, right click and select "Insert Group". On the Group Details wizard, we will select the item to group on (here, "Writer::name") and the type of sorting we want to perform (here, "Writer::name" in ascending order).
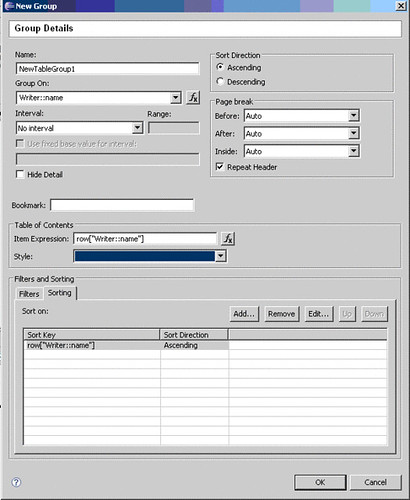
The configuration of filters and sorters.
The resulting report should consistently contain sorted, unique results.
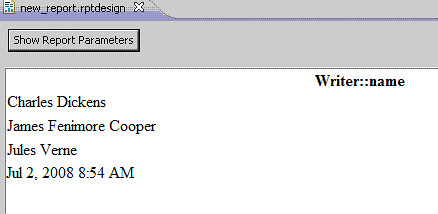
Duplicates are removed and writers' names appear alphabetically.
